The title is pretty self explanatory really, I’m going to run through what Zerto Backup for SaaS is, how it works and some of the advantages I see of using it.
The What?
Well the naming of the product couldn’t be more explanatory really, it is Zerto’s offering for backing up your SaaS Data, very simple and easy to understand, no codename or fancy marketing titles, simply put backup your SaaS data with Zerto!
The Why?
As most of use use SaaS applications on a daily basis in our work environments and personal lives, it easy to forget that some of our most critical data sits inside of these SaaS applications. But surely Microsoft are backing up my data for me inside of my company email? The short answer… No, Microsoft advises, “We recommend that you regularly backup Your Content and Data that you store on the Services or store using Third-Party Apps and Services”. This is also true of Gartner and Forrester, aswell as data regulatory laws such as GDPR. Having an independant copy of your data outside of the provider can give many benefits, but data security and data availability are the two main reasons to choose an independant 3rd party provider.
The How?
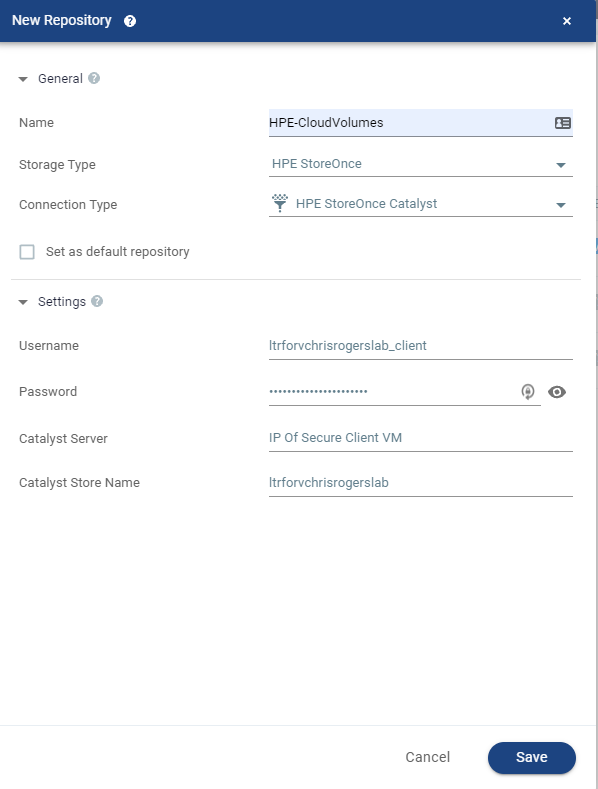
Zerto Backup for SaaS is powered by KeepIT, a leading provider in SaaS data protection therefore Zerto automatically becomes a prominent figure in this space by adopting industry leading technology as its foundation. Zerto Backup for SaaS offers users a simple way to backup, store and protect SaaS data, utilising a cloud to cloud model,
Zerto backup for SaaS stores data in the only cloud that is purpose built, designed and dedicated to SaaS data protection. This means storing a copy outside of any hyperscale public cloud such as AWS or Azure, which automatically guarantees that your live data is not sat in the same cloud as your Backup data.
Being SaaS to SaaS data protection offers many advantages, you dont need to run any additional infrastructure or manage any capacity or storage outside of the Zerto Backup for SaaS offering, this means complexity is minimal, capacity planning is non existent, storage and egress charges do not apply, and no longer to do organisations needs ot balance cost, retention and compliance, all 3 can be kept in check.
The Wow
Here are some of the key major benefits to using Zerto backup For SaaS.
- Unlimited Retentions – store as much data for as long as you want included in a per seat price
- Simple Pricing Model – Simply pay per user per month, no additonal costs or hidden fees such as storage, infrastructure or egress
- Preview Everything – See what your planning to restore before you restore it, saving time and copies of data restored that are not right.
- Comprehensive Coverage – One of the deepest and widest protection on the market for SaaS data
- Micrososft 365
- Salesforce
- Google Workspace
- Microsoft Dynamics 365
- Azure Active Directory (Free)
- ZenDesk
Summary
I know this is a very high level overview and some thoughts on the overall product itself, but I am going to be sharing more and more on Zerto Backup for SaaS in the future so keep an eye out for more detailed content coming soon.